基于BPE的子词压缩
对于英文语料来讲,特别是在预训练模型兴起之前,一种常见的分词方式是通过空格对英文语句直接进行分词。然而这种分词方式可能也会带来一些问题。
- 英文单词由于时态、单复数、大小写等因素,可能具有多个单词变体,比如单词go具有这样的变体: going, gone, goes,单纯基于空格从语料中收集单词,可能会导致词表过大,进而导致模型学习过程中,需要设置较大的词向量矩阵,增加模型参数。
- 由于词表难以穷尽所有单词,以及网络中会出现一些新的词,导致某些词无法出现在词表中,即出现集外词(OOV)。
BPE(Byte-Pair Encoding)是缓解这些问题的一种算法,其不再按照完整的单词进行分词,而是将单词划分成了子词(sub-word)的粒度。例如单词showed可以被划分为show和ed, 如此做法,可以有效缩减单词个数,同时通过拆解子词也能够缓解OOV问题。图1展示了一种BPE算法效果的示例,一方面通过右侧的子词组合可以表示左侧任意一个单词,另一方面通过子词的表示大大减小了原本词表的大小。
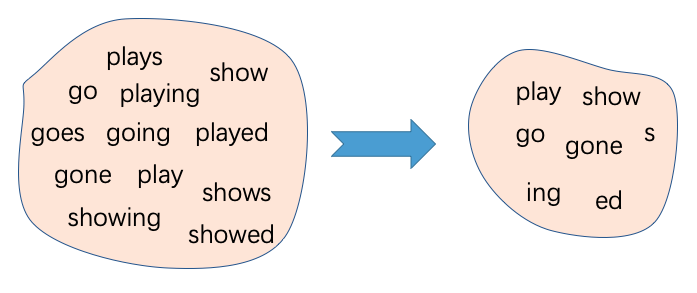
图1 BPE算法示例
1.2 实现流程
如图2所示,使用BPE算法进行对文本进行分词,首先需要根据英文语料构建BPE的子词词表,根据此词表即可对给定的文本序列进行编码,即分词,获取分词后的文本序列。同时提供根据编码后的结果还原原始语句的方法。
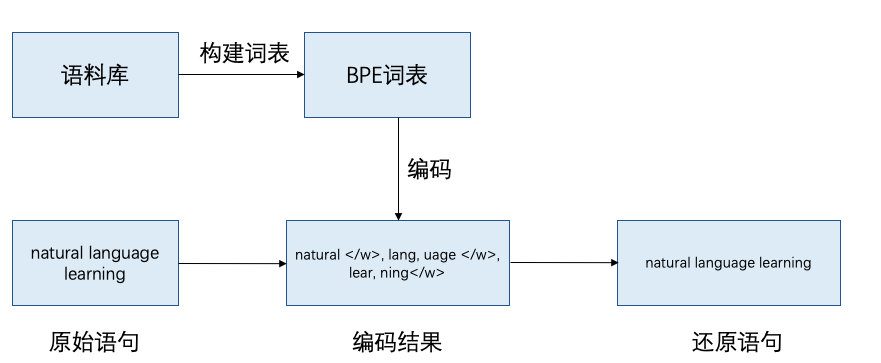
图2 BPE实现流程
1.3 词表构建
词表构建是BPE算法的核心,首先需要准备一批语料,然后从语料中逐步统计词频,构建BPE子词词表。具体来讲,首先需要将训练数据中的每个单词切分成字符作为初始子词,并统计语料中的子词初始化子词词表。接下来,可以按照如下步骤逐步迭代:
- 统计每一个连续子词对的出现频率,选择最高频子词对合并成新的子词,并将该子词对加入词表中;
- 根据最高频子词对,将语料中的这两个相邻子词进行合并;
- 如果组成最高频子词对的子词在原始语料中不再存在,则在词表中进行删除;
- 重复第1-3步直到达到设定的子词词表大小或迭代次数;
下面通过一个例子说明如何构造子词词典,假设通过统计获得了如下预处理好的语料库,其中每个单词中的字符通过空格进行分割为子词,同时单词后使用作为单词结尾符号:
train_data = {'d e e p </w>': 5, 'l e a r n i n g </w>': 7, 'n a t u r a l </w>': 6, 'l a n g u a g e </w>': 3,'p r o c e s s i n g </w>':7}
利用以上训练数据,初始化子词词表为:
bpe_vocab = {'a', 'e', 'p', '</w>', 'g', 'o', 's', 'l', 'r', 'u', 'd', 'n', 'i', 't', 'c'}
接下来,便可以逐步统计最高频的相邻子词对,并对训练数据进行子词合并。
第1次迭代: 最高频连续子词对"n"和"g"出现了7+3+7=17次,合并成"ng"加入词表。"n"和"g"在语料库中依旧存在,因此不需要在词表中删除,语料库和词表在本次迭代之后的结果为:
train_data = {'d e e p </w>': 5, 'l e a r n i ng </w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3,'p r o c e s s i ng </w>':7}
bpe_vocab = {'a', 'e', 'p', '</w>', 'g', 'o', 's', 'l', 'r', 'u', 'd', 'n', 'i', 't', 'c', 'ng'}
第2次迭代: 最高频连续子词对"i"和"ng"出现了7+7=14次,合并成"ing"加入词表。子词"i"在语料库中不再存在,因此在词表中进行删除,语料库和词表在本次迭代之后的结果为:
train_data = {'d e e p </w>': 5, 'l e a r n ing </w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3,'p r o c e s s ing </w>':7}
bpe_vocab = {'a', 'e', 'p', '</w>', 'g', 'o', 's', 'l', 'r', 'u', 'd', 'n', 't', 'c', 'ng', 'ing'}
第3次迭代: 最高频连续子词对"ing"和""出现了7+7=14次,合并成"ing"加入词表。"ing"在语料库中不再存在,因此在词表中进行删除,语料库和词表在本次迭代之后的结果为:
train_data = {'d e e p </w>': 5, 'l e a r n ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3,'p r o c e s s ing</w>':7}
bpe_vocab = {'a', 'e', 'p', '</w>', 'g', 'o', 's', 'l', 'r', 'u', 'd', 'n', 't', 'c', 'ng','ing</w>'}
重复以上迭代过程,直到子词词表规模达到预先设定的大小或下一个最高频的子词对出现频率为1。
首先,定义函数get_subwords,用以统计子词以及对应的词频,并获取初始化后的子词词表bpe_vocab。
import re
import collections
def get_subwords(data):
"""
统计子词以及对应的词频
"""
subwords = collections.defaultdict(int)
for word, freq in data.items():
for subword in word.split():
subwords[subword] += freq
return subwords
train_data = {'d e e p </w>': 5, 'l e a r n i n g </w>': 7, 'n a t u r a l </w>': 6, 'l a n g u a g e </w>': 3,'p r o c e s s i n g </w>':7}
subwords = get_subwords(train_data)
# 获取初始化的子词词表
bpe_vocab = set(subwords.keys())
print("词表:", bpe_vocab)
词表: {'d', 's', 'a', 'u', 'o', '</w>', 'i', 'g', 'c', 'r', 'l', 't', 'n', 'p', 'e'}
接下来,在构造词表过程中,需要统计相邻子词对的词频,以便获取最高频的词对,代码实现如下。
def get_pair_with_frequency(data):
"""
获取子词对以及子词集合
"""
pairs = collections.defaultdict(int)
for word, freq in data.items():
sub_words = word.split()
for i in range(len(sub_words)-1):
pair = (sub_words[i],sub_words[i+1])
pairs[pair] += freq
return pairs
pairs = get_pair_with_frequency(train_data)
print("子词词对:", pairs)
best_pair = max(pairs, key=pairs.get)
print("当前最高频的子词对: ", best_pair)
子词词对: defaultdict(<class 'int'>, {('d', 'e'): 5, ('e', 'e'): 5, ('e', 'p'): 5, ('p', '</w>'): 5, ('l', 'e'): 7, ('e', 'a'): 7, ('a', 'r'): 7, ('r', 'n'): 7, ('n', 'i'): 7, ('i', 'n'): 14, ('n', 'g'): 17, ('g', '</w>'): 14, ('n', 'a'): 6, ('a', 't'): 6, ('t', 'u'): 6, ('u', 'r'): 6, ('r', 'a'): 6, ('a', 'l'): 6, ('l', '</w>'): 6, ('l', 'a'): 3, ('a', 'n'): 3, ('g', 'u'): 3, ('u', 'a'): 3, ('a', 'g'): 3, ('g', 'e'): 3, ('e', '</w>'): 3, ('p', 'r'): 7, ('r', 'o'): 7, ('o', 'c'): 7, ('c', 'e'): 7, ('e', 's'): 7, ('s', 's'): 7, ('s', 'i'): 7})
当前最高频的子词对: ('n', 'g')
接下来,根据获取的最高频子词对,对训练语料中的相应子词进行合并,代码实现如下。
def merge_data_with_pair(pair, data):
"""
将语料中的最高频子词对进行合并
输入:
- pair: 最高频子词词对
- data: 字典形式,统计好的输入语料
"""
result = {}
bigram = re.escape(' '.join(pair))
p = re.compile(r'(?<!\S)' + bigram + r'(?!\S)')
for word in data:
merged_word = p.sub(''.join(pair), word)
result[merged_word] = data[word]
return result
train_data = merge_data_with_pair(best_pair, train_data)
print("语料库: ", train_data)
语料库: {'d e e p </w>': 5, 'l e a r n i ng </w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s i ng </w>': 7}
最后,将最高频的子词对加入词表,对于不再存在于语料库中的子词在词表中进行删除。基于上述这流程,下面正式定义构建词表函数build_vocab,代码实现如下。
def build_vocab(train_data, num_merges):
"""
根据训练语料构建词表
输入:
- train_data: 字典形式,统计好的输入语料
- num_merges: 迭代次数
"""
# 初始化词表
subwords = get_subwords(train_data)
bpe_vocab = set(subwords.keys())
print(bpe_vocab, len(bpe_vocab))
i = 1
# 逐步生成词表
for _ in range(num_merges):
# 根据语料统计相邻子词对的词频
pairs = get_pair_with_frequency(train_data)
# 取频率最大的子词对, 如果pairs 为空或子词对的最大频次为1,则停止
if not pairs:
break
best_pair = max(pairs, key=pairs.get)
if pairs[best_pair] == 1:
break
# 合并语料
train_data = merge_data_with_pair(best_pair, train_data)
# 将子词加入词表中
merged_word = "".join(best_pair)
bpe_vocab.add(merged_word)
# 删除子词
subwords = get_subwords(train_data)
if best_pair[0] not in subwords:
bpe_vocab.remove(best_pair[0])
if best_pair[1] not in subwords:
bpe_vocab.remove(best_pair[1])
print("Iter - {}, 最高频子词对: {}".format(i, best_pair))
print("训练数据: ", train_data)
print("词表: {}, {}\n".format(len(bpe_vocab), bpe_vocab))
i += 1
return bpe_vocab
num_merges = 14
train_data = {'d e e p </w>': 5, 'l e a r n i n g </w>': 7, 'n a t u r a l </w>': 6, 'l a n g u a g e </w>': 3,'p r o c e s s i n g </w>':7}
bpe_vocab = build_vocab(train_data, num_merges)
print("词表: ", bpe_vocab)
{'d', 's', 'a', 'u', 'o', '</w>', 'i', 'g', 'c', 'r', 'l', 't', 'n', 'p', 'e'} 15
Iter - 1, 最高频子词对: ('n', 'g')
训练数据: {'d e e p </w>': 5, 'l e a r n i ng </w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s i ng </w>': 7}
词表: 16, {'d', 's', 'a', 'u', 'o', '</w>', 'i', 'g', 'c', 'r', 'ng', 'l', 't', 'n', 'p', 'e'}
Iter - 2, 最高频子词对: ('i', 'ng')
训练数据: {'d e e p </w>': 5, 'l e a r n ing </w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing </w>': 7}
词表: 16, {'d', 'ing', 's', 'a', 'u', 'o', '</w>', 'g', 'c', 'r', 'ng', 'l', 't', 'n', 'p', 'e'}
Iter - 3, 最高频子词对: ('ing', '</w>')
训练数据: {'d e e p </w>': 5, 'l e a r n ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 16, {'d', 's', 'a', 'u', 'o', '</w>', 'g', 'c', 'r', 'ng', 'l', 't', 'n', 'p', 'ing</w>', 'e'}
Iter - 4, 最高频子词对: ('l', 'e')
训练数据: {'d e e p </w>': 5, 'le a r n ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', '</w>', 'g', 'p', 'e', 'r', 'ing</w>', 'd', 'le', 's', 'ng', 't', 'o'}
Iter - 5, 最高频子词对: ('le', 'a')
训练数据: {'d e e p </w>': 5, 'lea r n ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', '</w>', 'g', 'p', 'e', 'lea', 'r', 'ing</w>', 'd', 's', 'ng', 't', 'o'}
Iter - 6, 最高频子词对: ('lea', 'r')
训练数据: {'d e e p </w>': 5, 'lear n ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', '</w>', 'g', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'lear', 'ng', 't', 'o'}
Iter - 7, 最高频子词对: ('lear', 'n')
训练数据: {'d e e p </w>': 5, 'learn ing</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', '</w>', 'g', 'learn', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't', 'o'}
Iter - 8, 最高频子词对: ('learn', 'ing</w>')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'p r o c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't', 'o'}
Iter - 9, 最高频子词对: ('p', 'r')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'pr o c e s s ing</w>': 7}
词表: 18, {'a', 'u', 'c', 'l', 'n', 'learning</w>', '</w>', 'g', 'pr', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't', 'o'}
Iter - 10, 最高频子词对: ('pr', 'o')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'pro c e s s ing</w>': 7}
词表: 17, {'a', 'u', 'c', 'l', 'n', 'learning</w>', '</w>', 'g', 'pro', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't'}
Iter - 11, 最高频子词对: ('pro', 'c')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'proc e s s ing</w>': 7}
词表: 16, {'proc', 'a', 'u', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't'}
Iter - 12, 最高频子词对: ('proc', 'e')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'proce s s ing</w>': 7}
词表: 16, {'a', 'u', 'l', 'n', 'learning</w>', 'proce', '</w>', 'g', 'p', 'e', 'r', 'ing</w>', 'd', 's', 'ng', 't'}
Iter - 13, 最高频子词对: ('proce', 's')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'proces s ing</w>': 7}
词表: 16, {'a', 'u', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'proces', 'r', 'ing</w>', 'd', 's', 'ng', 't'}
Iter - 14, 最高频子词对: ('proces', 's')
训练数据: {'d e e p </w>': 5, 'learning</w>': 7, 'n a t u r a l </w>': 6, 'l a ng u a g e </w>': 3, 'process ing</w>': 7}
词表: 15, {'a', 'u', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'r', 'process', 'ing</w>', 'd', 'ng', 't'}
词表: {'a', 'u', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'r', 'process', 'ing</w>', 'd', 'ng', 't'}
1.4 语料编码
在获得子词词表之后,便可以根据该词表将文本序列进行编码,即分词。这里可以采用贪心的思想,根据子词词表中的子词长度对子词词表由大到小进行排序,然后对于一个待编码的单词,从前向后依次遍历词表中的子词,如果该子词在单词之后,则将该单词在子词位置进行切分,这样便可以获得最多三个单词子串:子词前的单词子串、子词串、子词后的单词子串,然后按照同样的思路继续遍历剩余的单词子串。如果在子词词表遍历完成之后,依然有一些单词子串没有被切分,则使用'
下面来看一个例子,假设给定子词词表为:
[“ning</w>”, “lear”, “deep</w>”, “est</w>”, “the</w>”, “a</w>”]
待分词的文本序列为:
[“the</w>”, “deep</w>”, “learning</w>”]
则最后分词编码的结果为:
[“the</w>”, “deep</w>”, "lear", “ning</w>”]
接下来,先定义函数tokenize_word用于对单词进行编码。
import re
def tokenize_word(word, sorted_vocab, unknown_token='<unk>'):
"""
输入:
- word: 待编码的单词
- sorted_vocab: 排序后的子词词典
- unknown_token: 不能被切分的子词替代符
"""
# 如果传入的词为空
if word == "":
return []
# 如果词表为空,则将输入的词替换为<UNK>
if sorted_vocab == []:
return [unknown_token] + len(string)
word_tokens = []
# 遍历词表拆分单词
for i in range(len(sorted_vocab)):
token = sorted_vocab[i]
# 基于该token定义正则,同时将token里面包含句号的变成[.]
token_reg = re.escape(token.replace('.', '[.]'))
# 在当前word中进行遍历,找到匹配的token的起始和结束位置
matched_positions = [(m.start(0), m.end(0)) for m in re.finditer(token_reg, word)]
# 如果当前token没有匹配到相应串,则跳过
if len(matched_positions) == 0:
continue
# 获取匹配到的子串的起始位置
end_positions = [matched_position[0] for matched_position in matched_positions]
start_position = 0
for end_position in end_positions:
subword = word[start_position: end_position]
word_tokens += tokenize_word(subword, sorted_vocab[i+1:], unknown_token)
word_tokens += [token]
start_position = end_position + len(token)
# 匹配剩余的子串
word_tokens += tokenize_word(word[start_position:], sorted_vocab[i+1:], unknown_token)
break
else:
# 如果word没有被匹配,则映射为<unk>
word_tokens = [unknown_token] * len(word)
return word_tokens
定义函数tokenize用于对语句进行编码。
def tokenize(text, bpe_vocab):
"""
使用BPE对输入语句进行编码
"""
# 对子词词表按照子词长度进行排序
sorted_vocab = sorted(bpe_vocab, key=lambda subword: len(subword), reverse=True)
print("待编码语句: ", text)
tokens = []
for word in text.split():
word = word + "</w>"
word_tokens = tokenize_word(word, sorted_vocab, unknown_token='<unk>')
tokens.extend(word_tokens)
return tokens
text = "natural language processing"
tokens = tokenize(text, bpe_vocab)
print("词表: ", bpe_vocab)
print("编码结果: ", tokens)
待编码语句: natural language processing
词表: {'a', 'u', 'l', 'n', 'learning</w>', '</w>', 'g', 'p', 'e', 'r', 'process', 'ing</w>', 'd', 'ng', 't'}
编码结果: ['n', 'a', 't', 'u', 'r', 'a', 'l', '</w>', 'l', 'a', 'ng', 'u', 'a', 'g', 'e', '</w>', 'process', 'ing</w>']
1.5 语料解码
在将一串语句使用BPE进行编码后,如何还原成原来的语句呢。这种情况下,单词后设置的<\w>便起了作用。即可以一直合并分词后的子词,直到遇见<\w>便可以解码出一个完整单词。下面给出了一个例子。
假设使用BPE编码后的序列:
[“the</w>”, “deep</w>”, “lear”, “ning</w>”]
则对应的解码结果为:
["the", "deep","learning"]
代码实现如下。
def restore(tokens):
text = []
word = []
for token in tokens:
if token[-4:] == "</w>":
if token != "</w>":
word.append(token[:-4])
text.append("".join(word))
word.clear()
else:
word.append(token)
return text
tokens = ["the</w>", "deep</w>", "lear", "ning</w>"]
text = restore(tokens)
print("还原结果: ", text)
还原结果: ['the', 'deep', 'learning']

