GAN
使用 CIFAR-10 数据集,包含动物和交通工具的图片
生成器和判别器都使用 CNN
生成器:四层卷积,中间用 ReLU,最后用 Tanh
判别器:四层卷积,中间用 ReLU,最后用 Sigmoid
使用交叉熵损失函数
先训练判别器,给判别器真实图片和假图片,分别带有标签,来更新判别器参数
再训练生成器,让生成器生成图片,让判别器判断,更新生成器的参数,使判别器认为生成的是真实图片
CNN 人脸识别
首先进行三分类,小组同学三人,每人录制一个全方位的不同角度的面部视频,
使用openCV对视频进行分割,获得3000张左右不同角度、不同光照的人脸图片
CNN:使用alexnet架构,5层卷积,3层最大池化,使用 ReLU 激活,最后 softmax
手写数字
LeNet-5
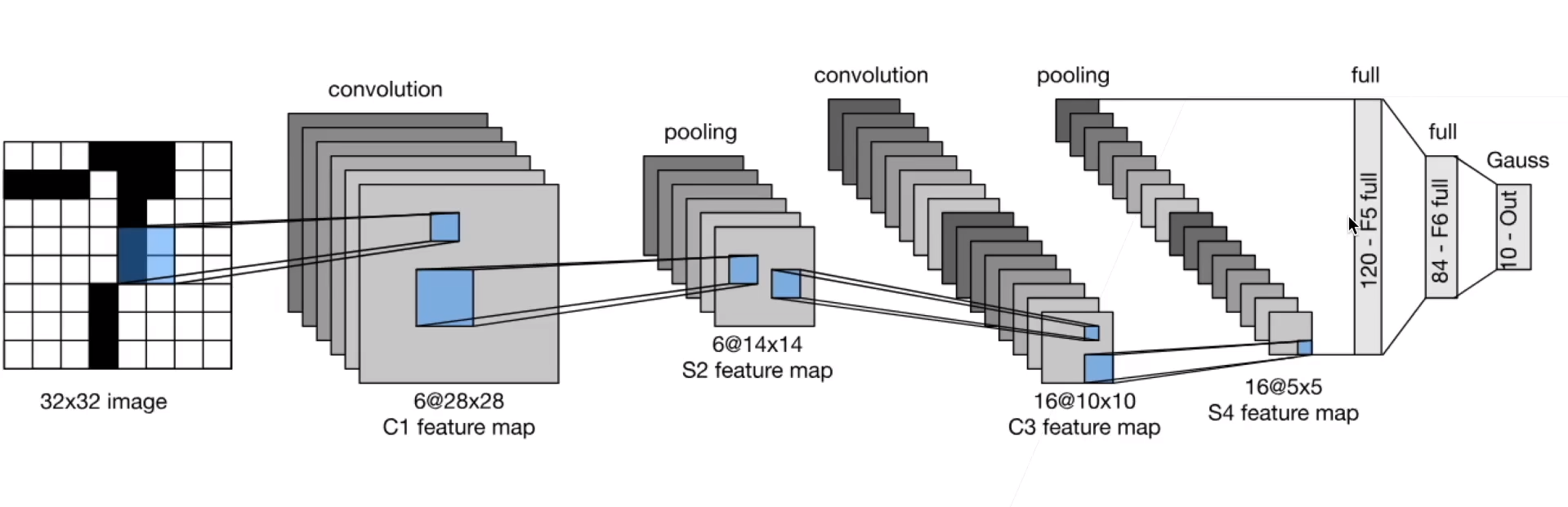
使用MNIST:28x28,第一层 padding=2,输入网络是 32x32
-
输入层(Input Layer):接受的输入图像大小通常是32x32像素。这是因为网络设计时考虑到数字的实际大小和希望网络能够捕捉到重要的特征。
-
第一卷积层(C1):这一层使用6个卷积核(或滤波器),每个大小为5x5,步长为1,无填充(padding),输出的特征图(feature map)大小为28x28x6。
-
第一下采样层(S2):也称为池化层,使用2x2的窗口进行平均池化,步长为2,将特征图的维度降低到14x14x6。这一步骤有助于减少数据的空间尺寸,从而减少计算量和控制过拟合。
-
第二卷积层(C3):这一层有16个卷积核,每个大小为5x5,处理上一层的输出,产生10x10x16的特征图。这一层的设计允许网络学习更高级的特征。
-
第二下采样层(S4):同样采用2x2平均池化,步长为2,输出的维度为5x5x16。
-
全连接层(F5):这一层有120个节点,它将前一层的输出展平(flatten)并全连接到这120个节点上。这一层开始将学到的特征组合成更高级别的模式。
-
第二全连接层(F6):这一层有84个节点,进一步处理特征,为最终的分类决策做准备。
-
输出层(Output Layer):最后是一个具有10个节点的输出层,对应于10个数字类(0到9)。这一层通常使用softmax激活函数,将网络的输出转换为概率分布。
两层卷积两层池化,卷积池化之间使用 Sigmoid 激活,最后使用全连接层映射到 10 个分类
光度立体法
对要检测物体在不同方向的光照条件下进行多次拍照。每次改变的只有光源的位置,确保光源的强度和颜色保持一致。
结合不同光照下的像素亮度值,使用最小二乘法计算每个像素点处的表面法向量。用法向量重构三维物体
SIFT和词袋模型图片分类
使用 15-Scene 数据集,包含 15 种不同类型的场景,例如办公室、厨房、卧室、客厅、乡村、海滩等。
共4400张左右,7比3的比例来划分训练集和测试集
原理
SIFT对每张图片生成不同个数的特征描述向量,将这些向量输入kmeans中,聚为300类,即构建了大小为300的视觉词汇表
使用bow对图像编码:
对于每张图像,将其SIFT特征向量与视觉词汇表中的词汇进行比较,找出每个特征向量最接近的视觉词。然后,为每张图像创建一个长度为k的向量(即BoW向量),其中每个元素记录了对应视觉词在该图像中出现的频率。
将图向量输入 svm,一对多将图片分为15类
RoBERTa 问答系统
SQuAD 数据集是斯坦福大学开发的一个流行的问答数据集,广泛用于自然语言处理中的机器阅读理解研究。SQuAD挑战模型根据给定的段落文本来回答问题。这些段落来自维基百科的文章,问题则是由人工撰写的。SQuAD的目标是推进计算机对自然语言的理解,特别是在问答系统的开发上。
使用transformer中预训练的 RoBERTa
KCF目标跟踪
原理
利用循环矩阵的特性来训练一个分类器,这个分类器用于区分目标和背景。它是基于前一帧的目标位置来预测当前帧的目标位置。这种方法允许算法在每一帧中快速更新模型,以适应目标的运动和外观的变化。
相关滤波、循环矩阵、快速傅里叶变换、核技巧
- 使用循环矩阵对目标进行平移,生成训练样本(数据增强),训练一个能检测目标位置的相关滤波器
- 使用相关滤波器,对连续视频帧中不同位置的候选区滤波并评分,得分最高的位置是目标的当前位置
- 快速傅里叶变换被用来加速相关滤波的计算。通过将图像和滤波器都转换到频域,点乘操作可以用来替代复杂的卷积操作,从而显著提高算法的计算效率。
- 通过选择合适的核函数(如高斯核),算法能够在高维特征空间中更好地区分目标和背景,即使目标的外观发生了较大变化。
步骤
-
初始化:在视频的第一帧中,在视频中选定一个框,KCF算法利用这个初始框来提取目标的特征。这些特征包括原始像素值、颜色直方图、特征信息等。
-
训练分类器:用循环矩阵构建训练集,使得可以高效地利用所有平移版本的训练样本,训练滤波器找,到最佳的滤波器系数。这个过程中还可以通过引入核技巧来处理非线性特征映射。
-
检测:不断读取视频帧,在随后的每一帧中,KCF算法首先在目标的预期位置附近提取特征,然后使用之前训练的分类器(滤波器)对这些位置进行评分,以判断目标最可能的新位置。
-
模型更新:通过设置一个学习率,使滤波器在更新位置的过程中在旧的信息基础上更新模型,来保证对新变化的适应性
-
循环:步骤3和步骤4在视频的每一帧中重复执行,以此实现对目标的连续跟踪。
TF-IDF
数据预处理:去除无关字符(如HTML标签)、转换为小写、分词、去除停用词、进行词干提取或词形还原等
使用TF-IDF模型将文本数据转换为数值特征向量。
将特征值向量输入SVM,进行五分类
SVM五分类需要创建五个SVM模型,分别对每个类别和其他类别进行分类
最后评估
BiLSTM-CRF命名实体识别
人民日报 中文 NER 数据集
实体包括人名(PER)、地名(LOC)和组织机构名(ORG)。标注系统采用BIO系统,对数据集进行编码。
查看数据集信息,句子长度的3/4位点为58,那么可以设置最长句子长度为60,将所有句子填充到一样的长度
输入是一个原文文件,和一个标注文件
输入文本被转换成词向量序列。
BiLSTM层处理这些词向量,捕获每个词的双向上下文信息。
BiLSTM的输出被送入CRF层,CRF层利用这些信息以及标注之间的依赖关系,计算最可能的标注序列。
结果:输入一个句子,将其中的命名实体抽取出来,使用BIO系统标注
BPE
词汇表的准备:首先,需要将汉语文本中的所有词或汉字分割成基本单位。对于汉语来说,基本单位通常是单个汉字或字符。
初始化:算法以单个汉字或字符作为初始符号集合,并计算所有相邻符号对的出现频率。
合并阶段:
在每次迭代中,算法都会查找出现次数最多的相邻符号对。
这对最常见的符号被合并为一个新的符号,这个新的符号被加入到符号集合中。
例如,如果“的人”是最常见的符号对,那么它们会被合并为一个新的符号“的人”。
迭代:重复合并步骤,直到达到预定的合并操作次数,或者没有可以合并的符号对为止。合并的次数可以根据具体的任务和数据集来设定。
应用:一旦BPE模型训练完成,就可以用它来将新的文本分割成已知的子词单元。不在词汇表中的字或词会被进一步分割,直到分割成词汇表中的符号。
kaggle Titanic
以不同乘客特征作为输入,判断是否死亡
下载 train.csv、test.csv
读取数据,展示中位数、众数,判断缺失值个数,选择是填充还是删除
分析各个特征之间的关系,删除无用的,如果有效果相似的保留更好的,或者进行合并
使用 MLP、随机森林、SVM、决策树 等模型对数据进行分类
精度达到百分之九十左右
Linux 文件流
记录一个pid或者prog进程访问了哪些文件和IP地址,记录file被哪些进程访问,列出进程的PID、程序名、日期时间、访问模式。展示进程之间的父子关系,记录CPU和内存的使用情况

