【Transformer模型】曼妙动画轻松学,形象比喻贼好记
超强动画,一步一步深入浅出解释Transformer原理!
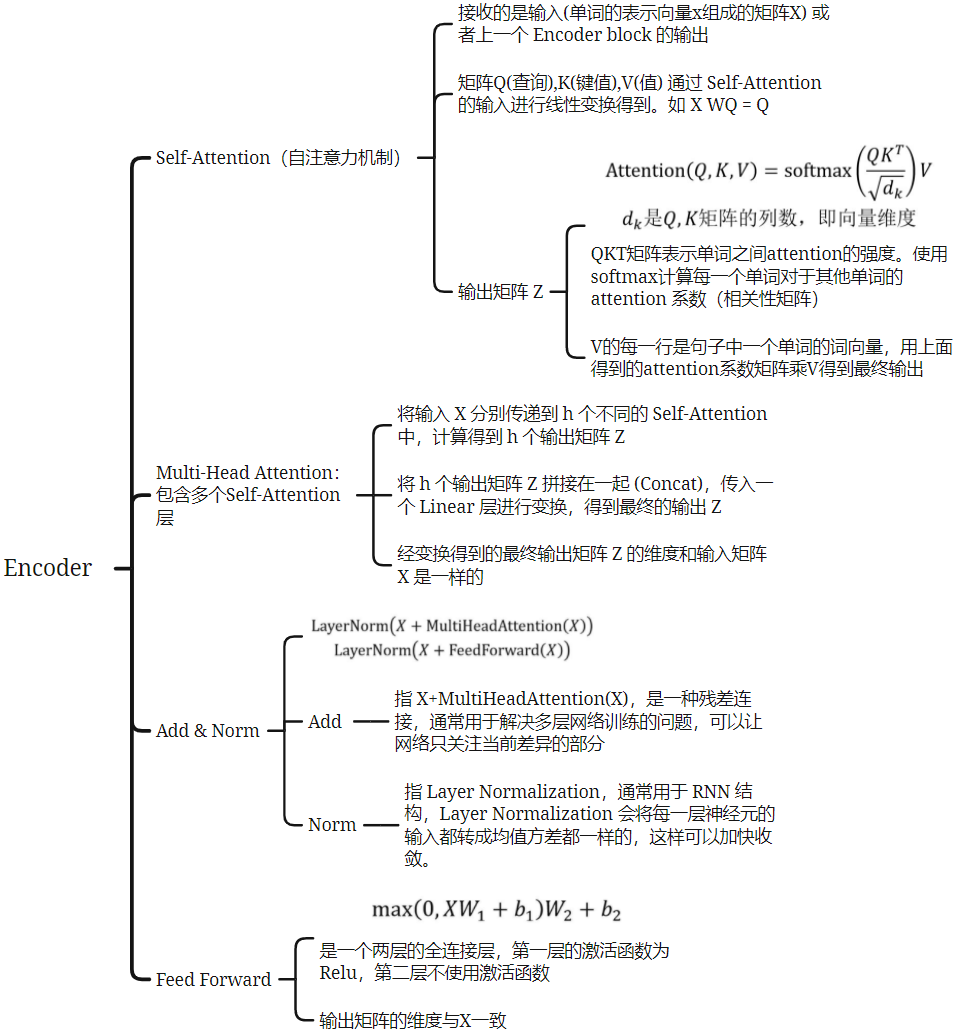
68 Transformer【动手学深度学习v2】
Transformer模型详解(图解最完整版)
【Transformer】10分钟学会Transformer | Pytorch代码讲解 | 代码可运行
Transformer论文逐段精读【论文精读】
Seq2Seq模型介绍
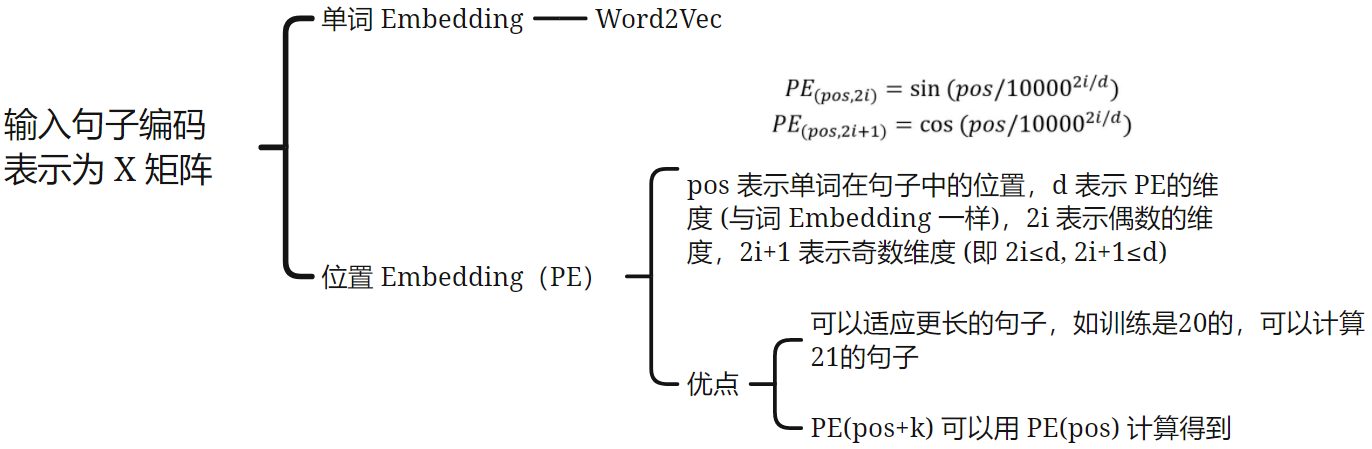
Transformer:Seq2Seq model with attention
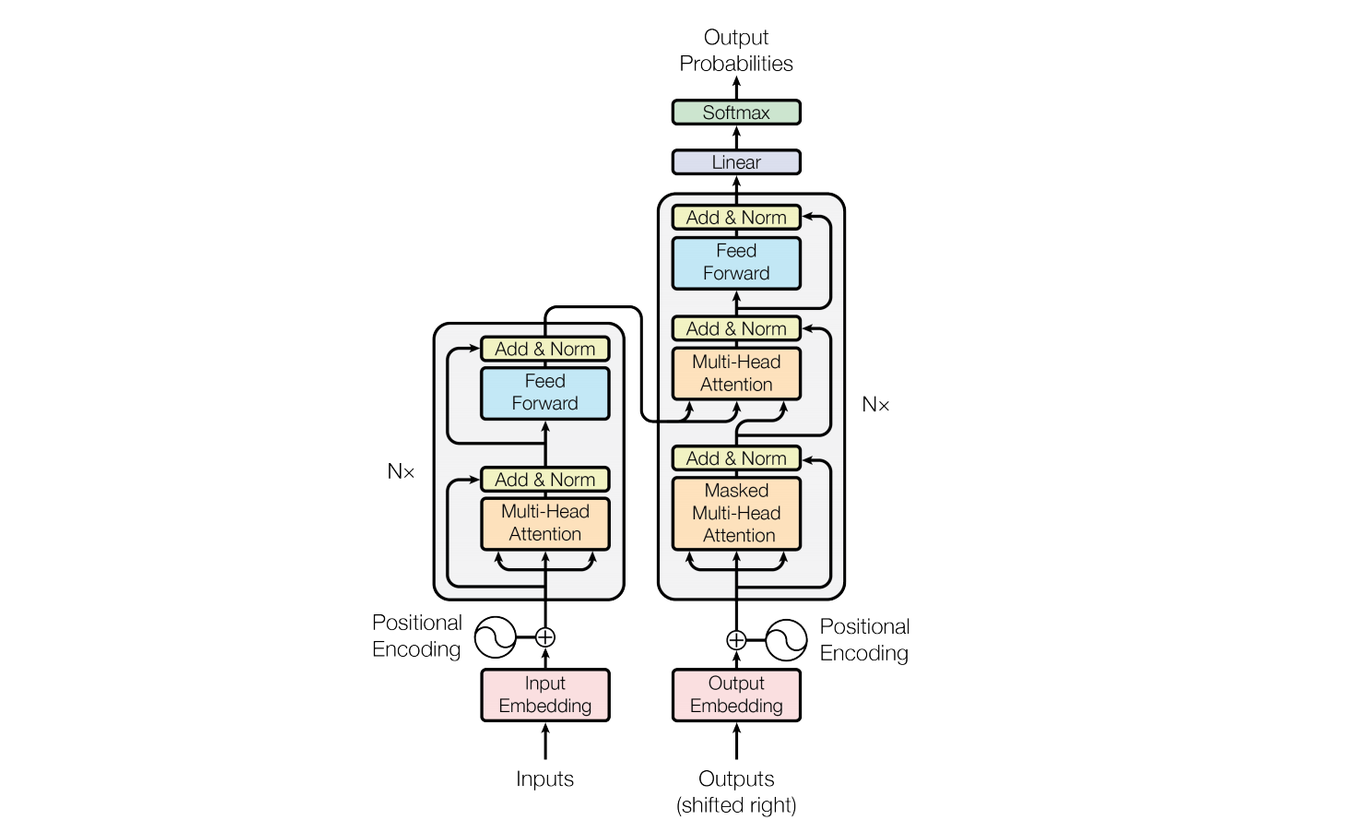
结构介绍
Attention
64 注意力机制【动手学深度学习v2】
09 Transformer 之什么是注意力机制(Attention)
Attention、Transformer公式推导和矩阵变化
和RNN的区别:RNN 是串行的,attention 是并行的。时序模型会占用很大的内存,而且容易遗忘前面学过的东西,transformer使用attention矩阵运算,使得数据可以并行计算,提升了效率
Query,Key,Value 的概念取自于信息检索系统,举个简单的搜索的例子来说。当你在某电商平台搜索某件商品(年轻女士冬季穿的红色薄款羽绒服)时,你在搜索引擎上输入的内容便是 Query。
然后搜索引擎根据 Query 为你匹配 Key(例如商品的种类,颜色,描述等)。
然后根据 Query 和 Key 的相似度,用 softmax 选择概率最大的,将结果和V相乘,得到 Value 中最匹配的内容。
相似度计算:QK 求内积(余弦相似度)
多头注意力机制是指,有n个自注意力模块,每个自注意力模块都有 QKV 三个矩阵。多头注意力的作用可以类比多卷积核,为了更好的提取特征
分为注意力、自注意力、带有mask的注意力
注意力:简单的 QKV
自注意力:QKV都来自于序列自己
带有mask的注意力:attention 每一次都可以看见完整的输入,而训练 decoder 的时候,由于要预测 t 时刻后的输入,所以 decoder 的 attention 是带 mask 的,保证在 t 时间输入后不会看见 t 时间之后的输入,确保模型在生成每个词时只能依赖于它之前的词,从而保持自回归特性。
Feed Forward
全连接层
Add&Norm
Add 是一个残差块,和 ResNet 中的一样,使得网络能做很深
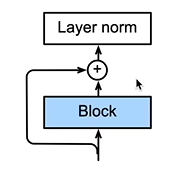
为什么采用 layer norm 而不是 batch norm:因为在语言 embedding 中,每个样本的长度可能不一样,所以以 batch 为单位进行标准化会有无用信息;而 layer norm 是将每个特征做标准化,效果更好
encoder-decoder
encoder和decoder是一一对应的,且encoder的输出维度等于decoder的输入维度
编码器的输出,将其作为解码器中第二层注意力的 key 和 value,其 query 来自目标序列
原文 encoder 和 decoder 都用了6个
思维导图

变体
Transformer 模型自从在 "Attention is All You Need" 论文中被首次提出以来,已经孕育出许多变体,这些变体针对不同的应用场景和性能优化进行了设计。以下是一些比较著名的 Transformer 模型变体:
-
BERT (Bidirectional Encoder Representations from Transformers): 由 Google 提出,BERT 通过双向训练的方式来更好地理解语言上下文,广泛应用于文本分类、命名实体识别、问答系统等领域。
-
GPT (Generative Pre-trained Transformer): OpenAI 开发的一系列模型,包括 GPT、GPT-2、GPT-3 等,主要用于文本生成任务,如文本续写、机器翻译、对话系统等。
-
Transformer-XL: 这个变体通过使用一个特殊的序列建模方式解决了标准 Transformer 在处理长序列时的限制,它能够在长序列文本上获得更好的性能。
-
XLNet: 结合了 Transformer-XL 和 GPT 的优点,使用了双向上下文和排列语言模型的训练方式,表现在很多自然语言处理任务中超越了 BERT。
-
RoBERTa (Robustly Optimized BERT approach): 是 BERT 的一个优化版本,通过更大规模的数据集和更长时间的训练,以及调整了一些超参数,来提高模型的性能。
-
ALBERT (A Lite BERT): 通过参数共享和因子化嵌入矩阵,显著减少了模型的大小,同时保持或超越了 BERT 的性能。
-
T5 (Text-to-Text Transfer Transformer): 将各种自然语言处理任务统一为一个文本到文本的框架,通过简化任务格式提高了模型的通用性和灵活性。
-
Electra: 通过引入更有效率的预训练任务(类似于GAN的判别器任务),在较小的计算预算下达到或超过了 BERT 的性能。
-
DeBERTa (Decoding-enhanced BERT with Disentangled Attention): 通过改进 BERT 的注意力机制,引入解耦注意力和增强的掩码解码器,提高了模型处理自然语言理解任务的能力。
-
ViT (Vision Transformer): 将 Transformer 应用于图像分类任务,通过将图像分割成多个小块(patches)并将它们作为序列输入到 Transformer 中,展示了 Transformer 架构在非NLP任务上的潜力。

