决策树是一种非常通用的机器学习算法,主要用于以下任务:
1. 分类
决策树经常用于分类任务。在这类任务中,目标是根据一系列输入特征将实例分配给预定义的类别。
例如,一个决策树可能用于基于病人的临床数据(如年龄、体重、血压等)来判断病人是否患有某种疾病。
2. 回归
决策树也可以用于回归任务,其中输出是一个连续值而非类别标签。回归树的构建与分类树类似,但在每个叶节点上,它们会预测一个连续值而不是类别标签。
例如,决策树可用于根据房屋的特征(如面积、房间数、地段等)预测房屋的市场价格。
3. 数据探索
由于决策树易于理解和解释,它们经常被用于数据探索。通过构建决策树,数据科学家可以了解哪些特征对输出变量有重要影响,以及这些特征是如何组合影响输出的。
这有助于生成有关数据的洞察,可能会指导进一步的分析。
4. 特征选择
在预处理阶段,决策树可以帮助识别最重要的特征,从而减少模型的复杂性和过拟合的风险。
特征重要性是根据特征在构建树时的使用频率和深度来评估的。
5. 多输出任务
决策树还可以扩展到多输出任务,其中一个实例可能有多个标签或多个连续输出。
例如,在环境监测中,一个模型可能需要根据一组传感器读数预测多种污染物的水平。
决策树因其简单、易解释的特性而受到广泛欢迎,尽管它们可能容易过拟合,
但通过技术如剪枝、随机森林和梯度提升树,可以有效地提高它们的泛化能力。
决策树的使用步骤
- 根据属性构建决策树(构建算法)
- 在新的数据上决策
决策树的构建
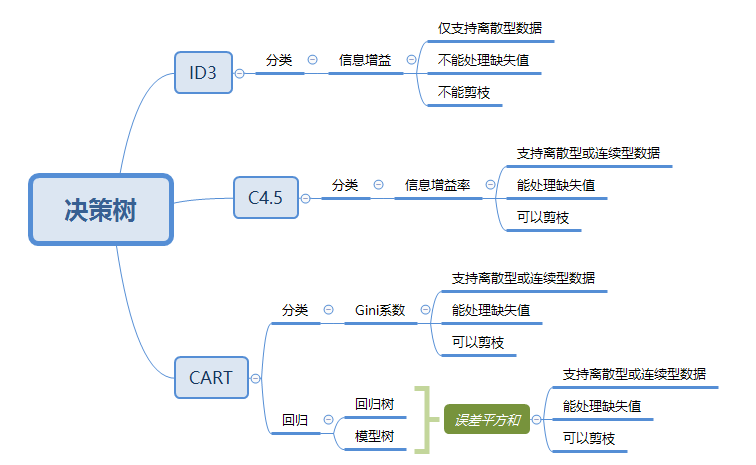
典型决策树算法:ID3、C4.5、CART
ID3用信息增益,C4.5用信息增益率,CART用Gini系数
构建原则:希望第一次分类就尽量分对,即优先选择使数据纯度提升的属性
ID3
决策树算法--ID3算法
信息熵:介于0-1之间,反映了数据纯度(和Gini系数一样)样本越纯,信息熵越趋于0,当A,B各占一半时,信息熵达到最大,值为1
信息熵公式讲解
信息增益:表示数据集 D 按照 A 属性划分后,D 的纯度。信息增益值越大,划分后的纯度越大。优先选择信息增益大的属性构建决策树
但若每个属性只有一个样本,那么信息增益为 0,无法划分,所以使用信息增益率,引出C4.5算法
C4.5算法
C4.5算法详解(非常仔细)
信息增益率引入了属性内部信息
算法步骤:
1)计算总信息熵 Entropy
2)分别计算每个属性信息熵
3)总信息熵 - 属性信息熵 得到信息增益 Gain(A)
4)计算信息增益率 GainRatio(A) = Gain / Ent
5)增益率max的为根节点
注意
总信息熵用结果的概率进行计算
属性信息熵:
∑( p(属性概率) * ∑ -( p(该属性内成功概率) log2 p + p(该属性内失败概率)log2 p ))
习题
https://zhuanlan.zhihu.com/p/166393579
CART(classification and regression tree)分类回归树
决策树算法--CART分类树算法
基尼系数:反映了数据的纯度(最上面视频有讲解和图像)
假设有两个类别 A,B,单类别占比越多,代表样本越纯
若全是 A / B 则基尼系数为 0,若 A、B 各占一半,则是数据最不纯的情况,Gini系数为 0.5
构建决策树时,优先选择Gini系数小的属性,意味着通过该属性分割后得到的子集在类别分布上更加纯粹,有助于提高决策树的分类性能。
决策树的剪枝
随机森林
【机器学习】动画讲解随机森林
【五分钟机器学习】随机森林(RandomForest):看我以弱搏强
随机森林是一种流行且强大的机器学习算法,属于集成学习方法的一种。它由多个决策树构成,通过组合多个决策树的预测结果来提高整体模型的准确性和鲁棒性。随机森林可以用于分类和回归任务,并且因其易于理解、实现简单和表现出色而广受欢迎。
工作原理
-
自助采样(Bootstrap sampling):从原始训练数据集中进行
有放回的随机采样来创建多个子集,每个子集用来训练一个决策树。 -
随机特征选择:在决策树的每个分裂过程中,随机森林不会考虑所有可能的特征,而是从全部特征中随机选择一个特征子集,并基于这个子集来选择最佳分裂特征。这一步增加了模型的多样性,有助于提高整体的泛化能力。
-
决策树集成:使用多个子集训练多个决策树,每个决策树都尽可能地生长到最大程度,不进行剪枝。最终的预测结果是通过对所有决策树的预测结果进行汇总得到的。对于分类任务,采用
投票机制(多数投票);对于回归任务,则采用平均值。
优点
- 准确性高:集成多个决策树可以减少模型的方差,提高预测准确性。
- 抗过拟合:相比于单个决策树,随机森林通过引入随机性和集成多个模型,能够有效地降低过拟合的风险。
- 适用性广:随机森林可以处理高维数据,并且不需要对数据进行太多的预处理,如归一化。
- 重要性评估:随机森林能够评估各个特征对模型预测能力的贡献,有助于特征选择。
缺点
- 模型解释性:虽然单个决策树容易理解,但是整个随机森林模型由于包含大量决策树,解释性不如单个决策树。
- 计算和内存开销:训练多个决策树需要较多的计算资源和内存,特别是当数据集很大时。
- 预测速度:随机森林在预测时需要汇总所有决策树的预测结果,可能会比单个决策树慢。
集成学习
boosting bagging stacking

