Seq2Seq
62 序列到序列学习(seq2seq)【动手学深度学习v2】
机器视觉算法是计算机视觉领域的关键组成部分,它使计算机能够通过图像和视频数据理解世界。这些算法可以根据它们的功能和用途进行分类。以下是一些常见的分类方式:
数据预处理是自然语言处理(NLP)任务中至关重要的一步,它直接影响到模型训练的效果和最终结果的质量。预处理步骤的目的是将原始文本转换成一种更易于计算机理解和处理的格式。以下是数据预处理中常见的几个步骤:
强化学习是机器学习的一个领域,它主要关注如何使智能体(Agent)在环境(Environment)中学会采取行动(Action)以最大化某种累积奖励(Reward)。强化学习与其他类型的机器学习(如监督学习和无监督学习)的主要区别在于,它不依赖于预先标记的输入/输出对,而是通过智能体与环境的交互来学习。以下是这些概念的详细介绍:
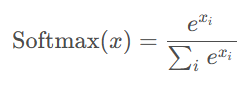
Softmax 函数如上图所示,分子 xi 是每个数据的值,将其指数化,将输出的数值拉开距离。分母是所有数据指数之和,这是一种概率形式,表达为样本占所有值的概率。
它可以用作 Softmax 回归、Softmax 激活函数在神经网络中往往用在最后一层,特别是在处理分类问题时,将网络的原始输出转换为更直观的概率形式。
模型复用,通常在机器学习和深度学习领域称为迁移学习(Transfer Learning),是一种非常有效的方法,可以将在一个任务上训练好的模型应用到另一个相关但不同的任务上。这种方法特别有用,因为从头开始训练一个复杂模型通常需要大量的计算资源和大量的标记数据,而这两者在很多情况下都是昂贵或难以获得的。
