数据预处理是自然语言处理(NLP)任务中至关重要的一步,它直接影响到模型训练的效果和最终结果的质量。预处理步骤的目的是将原始文本转换成一种更易于计算机理解和处理的格式。以下是数据预处理中常见的几个步骤:
【NLP】概述
任务
- 文本分类(Text Classification):将文本数据分类到预定义的类别中。常见的应用包括垃圾邮件检测、情感分析和主题分类。
【DL】强化学习
学习资源
动手学强化学习
https://hrl.boyuai.com/
【ML】Softmax
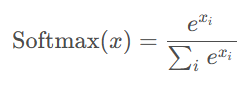
Softmax 函数如上图所示,分子 xi 是每个数据的值,将其指数化,将输出的数值拉开距离。分母是所有数据指数之和,这是一种概率形式,表达为样本占所有值的概率。
它可以用作 Softmax 回归、Softmax 激活函数在神经网络中往往用在最后一层,特别是在处理分类问题时,将网络的原始输出转换为更直观的概率形式。
【DL】模型复用
模型复用,通常在机器学习和深度学习领域称为迁移学习(Transfer Learning),是一种非常有效的方法,可以将在一个任务上训练好的模型应用到另一个相关但不同的任务上。这种方法特别有用,因为从头开始训练一个复杂模型通常需要大量的计算资源和大量的标记数据,而这两者在很多情况下都是昂贵或难以获得的。
Fine Tuning
模型复用的基本思想
【ML】分类和回归
分类
- 目标变量:分类任务中的目标变量是离散的,也就是说,它将输入数据映射到预定义的类别或标签中。这些类别通常是有限的且不连续的。
【ML】基础概念
Practical Machine Learning
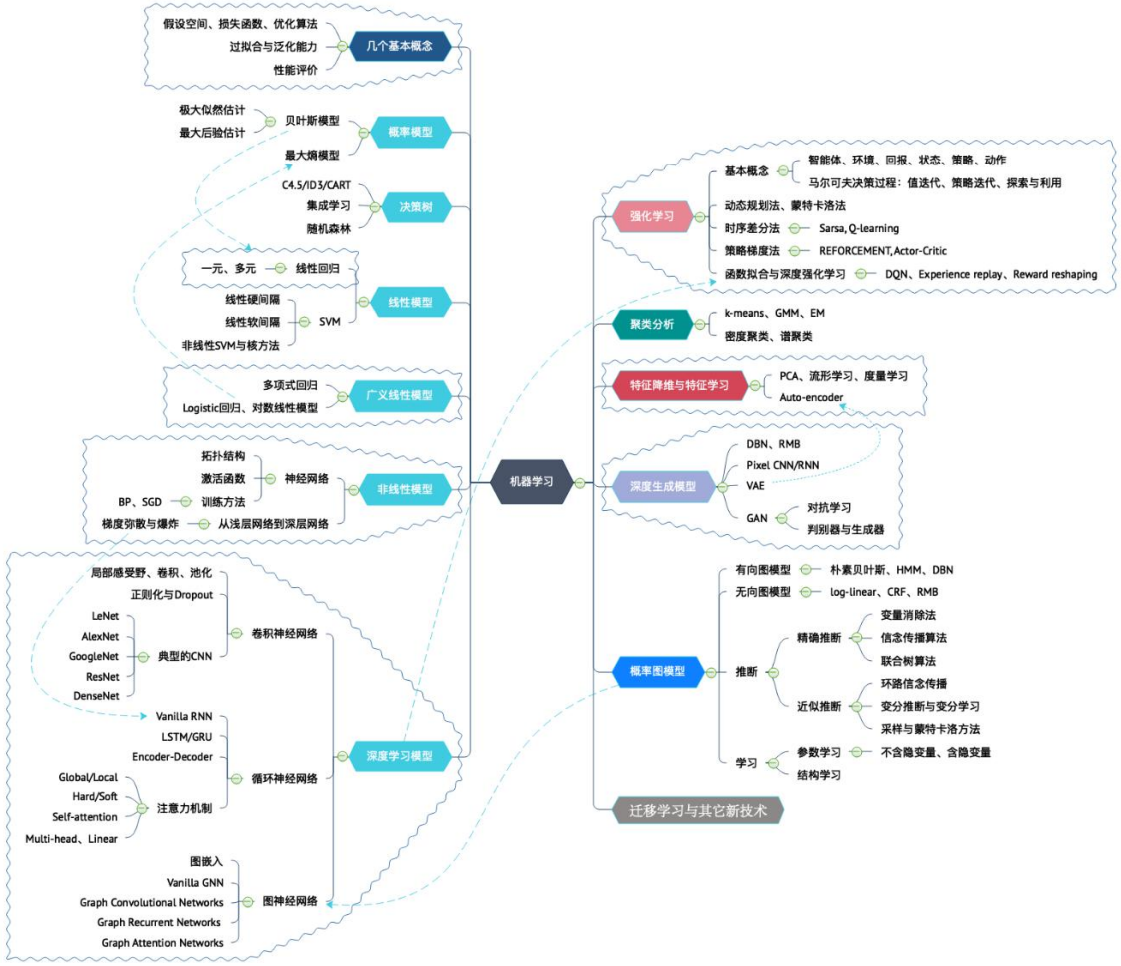
ML、DL 地图
0%
